Introduction
NVIDIA Bright Cluster Manager offers fast deployment, and end-to-end management for heterogeneous high-performance computing (HPC) and AI server clusters at the edge in the data center, and in multi/hybrid-cloud environments. It automates provisioning and administration for clusters ranging in size from a couple of nodes to hundreds of thousands. It also supports CPU-based and NVIDIA GPU-accelerated systems, and enables orchestration with Kubernetes.
Monitoring Use cases
- In case of any threshold breach or unexpected metric behavior, based on configurations the device monitoring helps to collect the metric values with respect to time and sends alerts to the intended customer team to act up immediately.
- It helps the customer with smooth functioning of business with minimal or zero downtime in case of any infrastructure related issues occurring.
Prerequisites
The OpsRamp Gateway must be installed.
Configure and install the integration
Go to Setup > Integrations and Apps.
Click + ADD on the INSTALLED APP page. The ADD APP page displays all the available applications along with the newly created application with the version.
Notes:- If there are already installed applications, it will redirect to the INSTALLED APPS page, where all the installed applications are displayed.
- If there are no installed applications, it will navigate to the ADD APP page.
- You can even search for the application using the search option available. Also you can use the All Categories option to search.
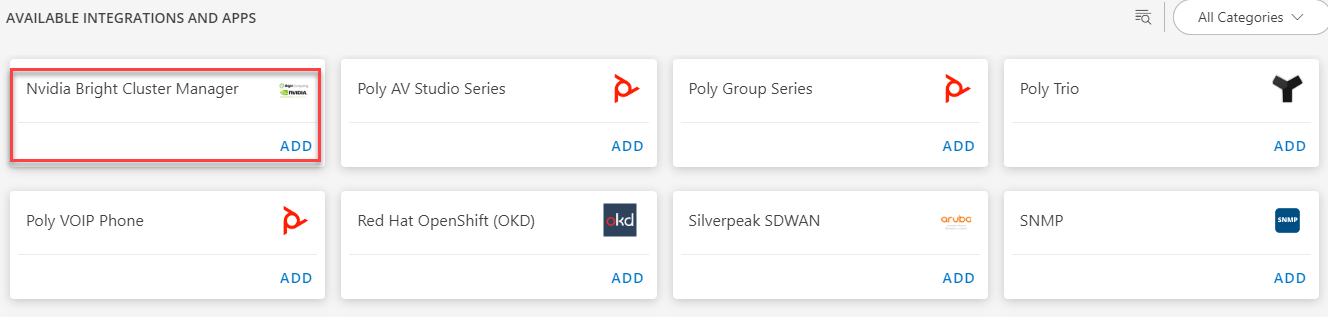
Click ADD in the Nvidia Bright Cluster Manager application.
In the Configurations page, click + ADD. The Add Configuration page appears.
Enter the below mentioned BASIC INFORMATION:
| Functionality | Description |
|---|---|
| Name | Enter the name for the configuration. |
| BCM Manager IP Address | Provide the BCM Manager IP Address. |
| BCM Manager Credentials | Select the credentials from the drop-down list. Note: Click + Add to create a credential. |
| CMSH Source Path in BCM Manager | Enter the source path for the BCM Manager. Note: By default /cm/local/apps/cmd/bin is provided. |
Note: Select App Failure Notifications; if turned on, you will be notified in case of an application failure that is, Connectivity Exception, Authentication Exception.
- In the RESOURCE TYPE section, select:
- ALL: All the existing and future resources will be discovered.
- SELECT: You can select one or multiple resources to be discovered.
- In the DISCOVERY SCHEDULE section, select Recurrence Pattern to add one of the following patterns:
- Minutes
- Hourly
- Daily
- Weekly
- Monthly
- Click ADD.

- Now the configuration is saved and displayed on the configurations page after you save it.
Note: From the same page, you may Edit and Remove the created configuration. - Click NEXT
- In the Installation page, select an existing registered gateway profile, and click FINISH.
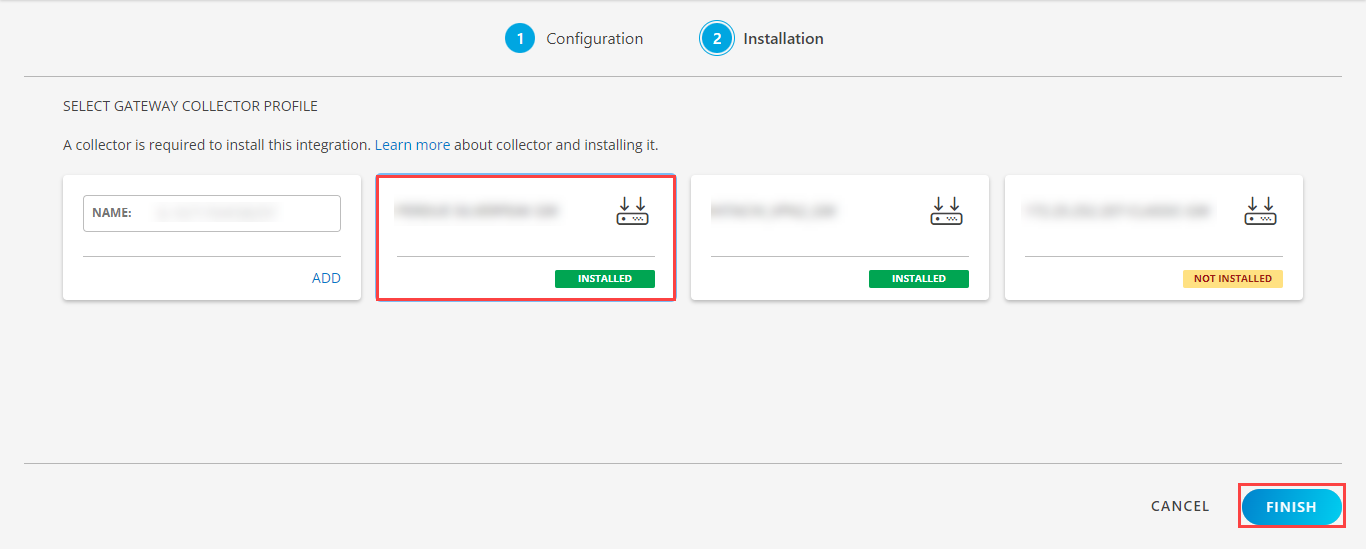
The application is now installed and displayed on the Installed Integration page. Use the search field to find the installed application.
Modify the Configuration
See Modify an Installed Integration or Application article.
Note: Select the Nvidia Bright Cluster Manager application.
View the NVIDIA Bright Cluster Manager details
The NVIDIA Bright Cluster Manager integration is displayed in the Infrastructure > Resources > Cluster. You can navigate to the Attributes tab to view the discovery details, and the Metrics tab to view the metric details for NVIDIA Bright Cluster Manager.

Supported metrics
| Native Type | Metric Name | Display Name | Units | Description | Metric Available from Application Version |
|---|---|---|---|---|---|
| Cluster | nvidia_bcm_cluster_nodeAvailabilityStatus | nvidia bcm cluster nodeAvailabilityStatus | NA | It monitors the availability status of each node. Below are the possible status values: UP-0, Down-1, Closed-2, installing-3, installer_failed-4, installer_rebooting-5, installer_callinginit-6, installer_unreachable-7, installer_burning-8, burning-9, unknown-10, opening-11, going_down-12, pending-13, no data-14 | 1.0.0 |
| nvidia_bcm_cluster_slurmDaemon_status | nvidia bcm cluster slurmDaemon status | NA | It monitors the running status of slurmDaemon & allocation status of the each node, Below are the possible states: allocated-0, idle-1, down-2 | 1.0.0 | |
| nvidia_bcm_cluster_gpuUnits_closed | nvidia bcm cluster gpuUnits closed | count | It monitors the count of how many GPU units in closed state | 1.0.0 | |
| nvidia_bcm_cluster_gpuUnits_down | nvidia bcm cluster gpuUnits down | count | It monitors the count of how many GPU units in Down state | 1.0.0 | |
| nvidia_bcm_cluster_gpuUnits_total | nvidia bcm cluster gpuUnits total | count | It monitors the count of total GPU units | 1.0.0 | |
| nvidia_bcm_cluster_gpuUnits_up | nvidia bcm cluster gpuUnits up | count | It monitors the count of how many GPU units are UP. | 1.0.0 | |
| nvidia_bcm_cluster_cpuIdle | nvidia bcm cluster cpuIdle | % | It monitors the % of CPU Idle Time. | 1.0.0 | |
| nvidia_bcm_cluster_nodesTotal | nvidia bcm cluster nodesTotal | count | It monitors the count of total number of nodes. | 1.0.0 | |
| nvidia_bcm_cluster_nodesUp | nvidia bcm cluster nodesUp | count | It monitors the count of how many nodes are in UP state. | 1.0.0 | |
| nvidia_bcm_cluster_nodesDown | nvidia bcm cluster nodesDown | count | It monitors the count of how many nodes are in DOWN state. | 1.0.0 | |
| nvidia_bcm_cluster_nodesClosed | nvidia bcm cluster nodesClosed | count | It monitors the count of how many nodes are in closed state. | 1.0.0 | |
| nvidia_bcm_cluster_devicesTotal | nvidia bcm cluster devicesTotal | count | It monitors the count of total devices. | 1.0.0 | |
| nvidia_bcm_cluster_devicesUp | nvidia bcm cluster devicesUp | count | It monitors the count of how many devices are in UP state. | 1.0.0 | |
| nvidia_bcm_cluster_devicesDown | nvidia bcm cluster devicesDown | count | It monitors the count of how many devices are in DOWN state. | 1.0.0 | |
| nvidia_bcm_cluster_coresUp | nvidia bcm cluster coresUp | count | It monitors the count of Cores which are in UP state. | 1.0.0 | |
| nvidia_bcm_cluster_coresTotal | nvidia bcm cluster coresTotal | count | It monitors the total count of cores | 1.0.0 | |
| nvidia_bcm_cluster_totalUsersLogin | nvidia bcm cluster totalUsersLogin | count | It monitors the count of total users login. | 1.0.0 | |
| nvidia_bcm_cluster_totalKnownUsers | nvidia bcm cluster totalKnownUsers | count | It monitors the count of total known users. | 1.0.0 | |
| nvidia_bcm_cluster_occupationRate | nvidia bcm cluster occupationRate | % | It monitors the Occupation rate in %. | 1.0.0 | |
| nvidia_bcm_cluster_cpuUtilization | nvidia bcm cluster cpuUtilization | % | It monitors the % of CPU Utilization | 1.0.0 | |
| nvidia_bcm_cluster_failedJobs | nvidia bcm cluster failedJobs | count | Returns number of failed jobs on the cluster. | 1.0.0 | |
| nvidia_bcm_cluster_queuedJobs | nvidia bcm cluster queuedJobs | count | Returns number jobs in queue on the cluster. | 1.0.0 | |
| nvidia_bcm_cluster_runningJobs | nvidia bcm cluster runningJobs | count | Returns number of jobs running on the cluster. | 1.0.0 | |
| nvidia_bcm_cluster_nodesInQueue | nvidia bcm cluster nodes InQueue | count | Returns number of nodes queued on the cluster | 1.0.0 | |
| nvidia_bcm_cluster_uniqueUserLogincount | nvidia bcm cluster uniqueUserLogincount | count | Returns number of unique users logged in to the cluster. | 1.0.0 | |
| nvidia_bcm_cluster_smartHdaTemp | nvidia bcm cluster smartHdaTemp | celsius | It monitors the temperature of spindle disks | 2.0.0 | |
| Head Node | nvidia_bcm_headNode_healthStatus | nvidia bcm headNode healthStatus | NA | Health status(PASS or FAIL) of each component. | 1.0.0 |
| nvidia_bcm_headNode_blockedProcesses | nvidia bcm headNode blockedProcesses | count | Blocked processes waiting for I/O. | 1.0.0 | |
| nvidia_bcm_headNode_systemCpuTime | nvidia bcm headNode systemCpuTime | jiffles | CPU time spent in system mode. | 1.0.0 | |
| nvidia_bcm_headNode_cpuWaitTime | nvidia bcm headNode cpuWaitTime | jiffles | CPU time spent in I/O wait mode. | 1.0.0 | |
| nvidia_bcm_headNode_errorsRecv | nvidia bcm headNode errorsRecv | Errors per Sec | Packets/s received with error. | 1.0.0 | |
| nvidia_bcm_headNode_errorsSent | nvidia bcm headNode errorsSent | Errors per Sec | Packets/s sent with error. | 1.0.0 | |
| nvidia_bcm_headNode_hardwareCorruptedMemory | nvidia bcm headNode hardwareCorruptedMemory | Bytes | Hardware corrupted memory detected by ECC. | 1.0.0 | |
| nvidia_bcm_headNode_memoryFree | nvidia bcm headNode memoryFree | GB | Free system memory. | 1.0.0 | |
| nvidia_bcm_headNode_gpu_utilization | nvidia bcm headNode gpu utilization | % | Average GPU utilization percentage. | 1.0.0 | |
| nvidia_bcm_headNode_gpu_temperature | nvidia bcm headNode gpu temperature | Celsius | GPU temperature. | 1.0.0 | |
| Physical Node | nvidia_bcm_physicalNode_healthStatus | nvidia bcm physicalNode healthStatus | NA | Health status(PASS or FAIL) of each component. | 1.0.0 |
| nvidia_bcm_physicalNode_blockedProcesses | nvidia bcm physicalNode blockedProcesses | count | Blocked processes waiting for I/O. | 1.0.0 | |
| nvidia_bcm_physicalNode_systemCpuTime | nvidia bcm physicalNode systemCpuTime | jiffles | CPU time spent in system mode. | 1.0.0 | |
| nvidia_bcm_physicalNode_cpuWaitTime | nvidia bcm physicalNode cpuWaitTime | jiffles | CPU time spent in I/O wait mode. | 1.0.0 | |
| nvidia_bcm_physicalNode_errorsRecv | nvidia bcm physicalNode errorsRecv | Errors per Sec | Packets/s received with error. | 1.0.0 | |
| nvidia_bcm_physicalNode_errorsSent | nvidia bcm physicalNode errorsSent | Errors per Sec | Packets/s sent with error. | 1.0.0 | |
| nvidia_bcm_physicalNode_hardwareCorruptedMemory | nvidia bcm physicalNode hardwareCorruptedMemory | Bytes | Hardware corrupted memory detected by ECC. | 1.0.0 | |
| nvidia_bcm_physicalNode_memoryFree | nvidia bcm physicalNode memoryFree | GB | Free system memory. | 1.0.0 | |
| nvidia_bcm_physicalNode_gpu_utilization | nvidia bcm physicalNode gpu utilization | % | GPU utilization percentage | 1.0.0 | |
| nvidia_bcm_physicalNode_gpu_temperature | nvidia bcm physicalNode gpu temperature | Celsius | GPU temperature. | 1.0.0 | |
| nvidia_bcm_physicalNode_nfsmount_totalSize | nvidia bcm physicalNode nfsmount totalSize | GB | It monitors the total size of the nfs mount file on the node. | 3.0.0 | |
| nvidia_bcm_physicalNode_nfsmount_usedSize | nvidia bcm physicalNode nfsmount usedSize | GB | It monitors the used size of the nfs mount file on the node. | 3.0.0 | |
| nvidia_bcm_physicalNode_nfsmount_utilization | nvidia bcm physicalNode nfsmount utilization | % | It monitors the percentage utilization of the nfs mount file on the node. | 3.0.0 |
Risks, Limitations & Assumptions
- Application can handle Critical/Recovery failure notifications for below two cases when user enables App Failure Notifications in configuration:
- Connectivity Exception (ConnectTimeoutException, HttpHostConnectException, UnknownHostException).
- Authentication Exception (UnauthorizedException).
- Application will not send any duplicate/repeat failure alert notification until the already existed critical alert is recovered.
- Application cannot control monitoring pause/resume actions based on above alerts.
- Metrics can be used to monitor NVIDIA Bright Cluster Manager resources and can generate alerts based on the threshold values.
- Macro replacement limitation (i.e, customization for threshold breach alert subject, description).
- Component level thresholds can be configured on each resource level.
- No support of showing activity log and applied time.
- No support for the option to get the latest snapshot metric.
- Application is not returning any data if any SSH connectivity issues (based on monitoring and discovery frequency our App will try to establish SSH connections to the target device).
- Application will work only with SSH credentials, with ssh port 22 in the open state.
- Application will not work for low monitoring frequencies. We recommend providing a minimum monitoring frequency of 15 minutes.
- Virtual Nodes discovery and Monitoring will not be supported.